La inferencia causal es el proceso de determinar si una relación entre variables es causal o meramente asociativa. En otras palabras, queremos saber si un cambio en una variable causa un cambio en otra.
NotaDefinición
La inferencia causal busca responder la pregunta: “¿Qué pasaría si…?” — una pregunta contrafactual que va más allá de la simple asociación estadística.
1.2 Correlación no implica causalidad
Este principio fundamental de la estadística nos recuerda que observar una asociación entre dos variables no significa que una cause la otra. Considera estos ejemplos:
Helados y ahogamientos: Las ventas de helado están correlacionadas con las muertes por ahogamiento. ¿Los helados causan ahogamientos? No — ambos aumentan en verano.
Cigüeñas y nacimientos: En algunas regiones europeas, el número de cigüeñas está correlacionado con la tasa de natalidad. ¿Las cigüeñas traen bebés? No — ambos están asociados con áreas rurales.
1.3 El problema fundamental de la inferencia causal
El problema fundamental de la inferencia causal es que no podemos observar el mismo individuo bajo dos condiciones diferentes al mismo tiempo. Si una persona recibe un tratamiento, no podemos saber qué hubiera pasado si no lo hubiera recibido.
Código
flowchart LR A[Individuo] --> B{Tratamiento} B -->|Sí| C[Resultado observado] B -->|No| D[Resultado contrafactual] style D stroke-dasharray: 5 5
flowchart LR
A[Individuo] --> B{Tratamiento}
B -->|Sí| C[Resultado observado]
B -->|No| D[Resultado contrafactual]
style D stroke-dasharray: 5 5
Figura 1.1: El contrafactual nunca se observa
1.4 Soluciones al problema
A lo largo de la historia, se han desarrollado diferentes enfoques para abordar este problema:
1.4.1 Experimentos aleatorizados
El ensayo clínico aleatorizado (RCT) es el estándar de oro porque:
La aleatorización crea grupos comparables
Elimina el sesgo de confusión
Permite estimar el efecto causal promedio
Sin embargo, los RCTs no siempre son: - Éticos (no podemos asignar exposiciones dañinas) - Factibles (alto costo, tiempo) - Generalizables (poblaciones seleccionadas)
1.4.2 Estudios observacionales
Los estudios observacionales son frecuentemente la única opción disponible. Para hacer inferencias causales válidas, necesitamos:
Identificar las fuentes de sesgo
Controlar la confusión
Evaluar la sensibilidad de los resultados
1.5 El enfoque de este libro
Este libro adopta un enfoque basado en Diagramas Acíclicos Dirigidos (DAGs), desarrollado principalmente por Judea Pearl (Pearl 2009). Este enfoque nos permite:
Determinar qué variables debemos (y no debemos) controlar
Código
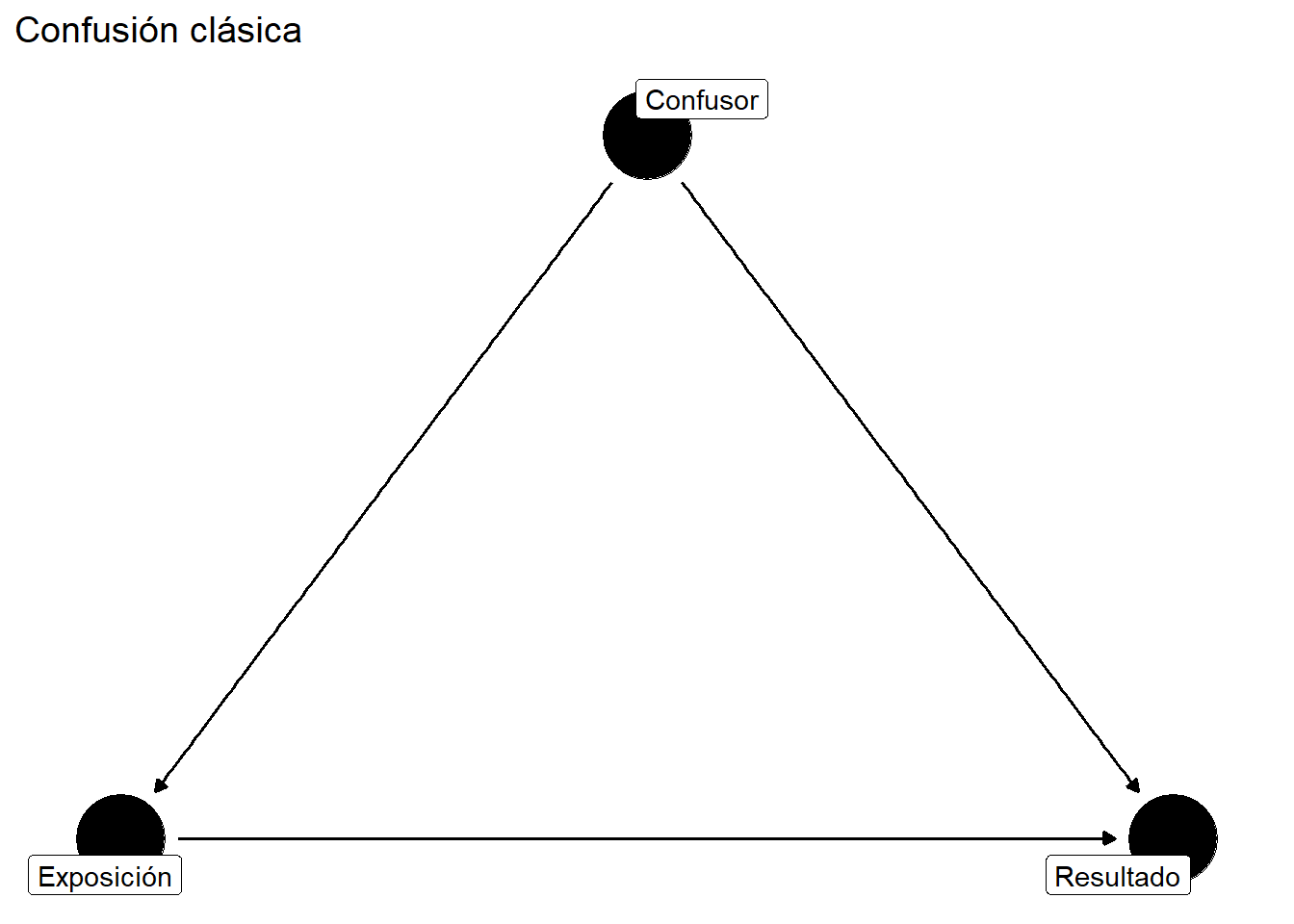
library(ggdag)library(ggplot2)dag <-dagify( Y ~ X + C, X ~ C,exposure ="X",outcome ="Y",labels =c(Y ="Resultado",X ="Exposición",C ="Confusor" ),coords =list(x =c(X =0, Y =2, C =1),y =c(X =0, Y =0, C =1) ))ggdag(dag, text =FALSE, use_labels ="label") +theme_dag() +labs(title ="Confusión clásica")
Figura 1.2: Un DAG simple mostrando confusión
1.6 Objetivos de aprendizaje
Al finalizar este libro, serás capaz de:
Construir e interpretar DAGs para problemas de investigación
Identificar y controlar fuentes de sesgo en estudios observacionales
Aplicar métodos de estratificación, matching y ponderación
Reconocer y manejar el sesgo de selección
Usar variables instrumentales cuando estén disponibles
Realizar análisis de supervivencia con enfoque causal
Evaluar la sensibilidad de tus resultados
Conducir análisis de mediación causal
Referencias
Pearl, Judea. 2009. Causality: Models, Reasoning, and Inference. 2nd ed. Cambridge: Cambridge University Press.
Ejecutar el código
# Introducción {#sec-intro}## ¿Qué es la inferencia causal?La **inferencia causal** es el proceso de determinar si una relación entre variables es causal o meramente asociativa. En otras palabras, queremos saber si un cambio en una variable *causa* un cambio en otra.::: {.callout-note}## DefiniciónLa inferencia causal busca responder la pregunta: *"¿Qué pasaría si...?"* — una pregunta contrafactual que va más allá de la simple asociación estadística.:::## Correlación no implica causalidadEste principio fundamental de la estadística nos recuerda que observar una asociación entre dos variables no significa que una cause la otra. Considera estos ejemplos:1. **Helados y ahogamientos**: Las ventas de helado están correlacionadas con las muertes por ahogamiento. ¿Los helados causan ahogamientos? No — ambos aumentan en verano.2. **Cigüeñas y nacimientos**: En algunas regiones europeas, el número de cigüeñas está correlacionado con la tasa de natalidad. ¿Las cigüeñas traen bebés? No — ambos están asociados con áreas rurales.## El problema fundamental de la inferencia causalEl **problema fundamental de la inferencia causal** es que no podemos observar el mismo individuo bajo dos condiciones diferentes al mismo tiempo. Si una persona recibe un tratamiento, no podemos saber qué hubiera pasado si no lo hubiera recibido.```{mermaid}%%| label: fig-counterfactual%%| fig-cap: "El contrafactual nunca se observa"flowchart LR A[Individuo] --> B{Tratamiento} B -->|Sí| C[Resultado observado] B -->|No| D[Resultado contrafactual] style D stroke-dasharray: 55```## Soluciones al problemaA lo largo de la historia, se han desarrollado diferentes enfoques para abordar este problema:### Experimentos aleatorizadosEl **ensayo clínico aleatorizado** (RCT) es el estándar de oro porque:- La aleatorización crea grupos comparables- Elimina el sesgo de confusión- Permite estimar el efecto causal promedioSin embargo, los RCTs no siempre son:- Éticos (no podemos asignar exposiciones dañinas)- Factibles (alto costo, tiempo)- Generalizables (poblaciones seleccionadas)### Estudios observacionalesLos **estudios observacionales** son frecuentemente la única opción disponible. Para hacer inferencias causales válidas, necesitamos:1. **Identificar** las fuentes de sesgo2. **Controlar** la confusión3. **Evaluar** la sensibilidad de los resultados## El enfoque de este libroEste libro adopta un enfoque basado en **Diagramas Acíclicos Dirigidos (DAGs)**, desarrollado principalmente por Judea Pearl [@pearl2009causality]. Este enfoque nos permite:- Representar visualmente nuestras asunciones causales- Identificar sistemáticamente las fuentes de sesgo- Determinar qué variables debemos (y no debemos) controlar```{r}#| label: fig-simple-dag#| fig-cap: "Un DAG simple mostrando confusión"#| code-fold: truelibrary(ggdag)library(ggplot2)dag <-dagify( Y ~ X + C, X ~ C,exposure ="X",outcome ="Y",labels =c(Y ="Resultado",X ="Exposición",C ="Confusor" ),coords =list(x =c(X =0, Y =2, C =1),y =c(X =0, Y =0, C =1) ))ggdag(dag, text =FALSE, use_labels ="label") +theme_dag() +labs(title ="Confusión clásica")```## Objetivos de aprendizajeAl finalizar este libro, serás capaz de:1. Construir e interpretar DAGs para problemas de investigación2. Identificar y controlar fuentes de sesgo en estudios observacionales3. Aplicar métodos de estratificación, matching y ponderación4. Reconocer y manejar el sesgo de selección5. Usar variables instrumentales cuando estén disponibles6. Realizar análisis de supervivencia con enfoque causal7. Evaluar la sensibilidad de tus resultados8. Conducir análisis de mediación causal## Referencias {.unnumbered}